Lately I’ve been working a lot with large bulk-loads of data between Oracle databases. The loading is done over db-links and we needed to speed up some of the loads since parallel DML is not supported in distributed transactions.
The project is a proof-of-concept (POC) for consolidating several databases into one large one. In the process we have to replace all primary and foreign keys to avoid duplicate values and maintain data integrity. The replacement is done by creating mapping-tables for every unique key and using these to replace column values appropriately throughout the tables. For example the EMP-table would get a shadow M$EMP-table with two columns: empno and empno_new. When we insert from the Source databases into the Target database, we would join these, something like this:
insert /*+append*/ into emp@targetdb select m_empno.empno_new, emp.ename, emp.job, m_mgr.mgr_new, emp.hiredate, emp.sal, emp.comm, m_dept.deptno_new from emp join m$emp m_empno on (emp.empno = m_empno.empno) left join m$emp m_mgr on (emp.mgr = m_mgr.mgr) left join m$dept m_deptno on (emp.deptno = m_deptno.deptno)
Join and left join will depend on the nature of the key/foreign key (weak/strong).
What we achieve with this method is:
- We replace all keys with new non-colliding ones (the creation of the mapping tables takes care of the starting offset-value for the keys)
- Every key will have one place (table) where we find the correct replacement value.
- The code can, for the vast majority of tables, be generated from the data dictionary (based on constraint information)
- We only read and write data once – no export (read-write) and import (read-write)
- No costly updates with undo-generation and unneccessary backup-volume. We don’t add columns and update them with new values.
On the down side we can get some large and wide joins. In one case we have a table with approximately 100 million rows and a join between one original data-table and 31 mapping tables. That means potentially over 3 billion new id’s to assign for this one table. (No it might not be pretty, but it’s real life…) The problem is that it starts to consume a lot of temp-space and thus reducing the total I/O-capacity on the Source-system. We’re not getting our CPUs to work:
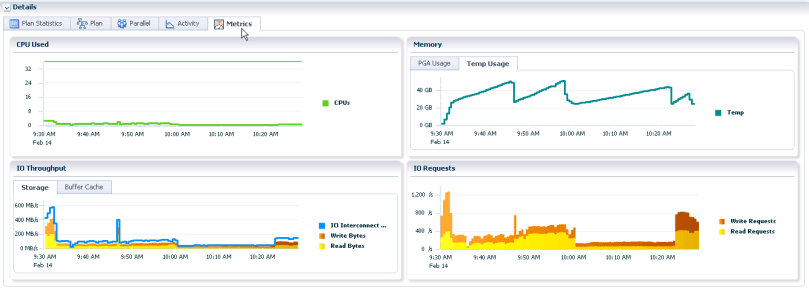
This query is the result of a large hash-join and was the plan that completed in the least amount of wall-time, but with a costly resource consumtion. I started to play a little bit with hints, and I found that I could reduce the resource consumtion, but the overall time went up. More on “the perfect insert” may come in another blog post later.
Another important thing to keep in mind about working over database links like this is that you can not parallellize queries over them.
So this load-query took about 1,5-2 hours to complete. That’s actually within our goal, but this creates the critical path for us and I wanted to reduce it, so it gave me the opportunity to play with the dbms_parallel_execute-package.
I wanted to check out two important factors:
- Can I parallellize this load?
- Can I reduce the working set, so that it fits in memory (PGA) and does not spill to temp-area on the disk, thereby reducing I/O?
Dbms_parallel_execute, takes a statement, generates a list of chunks to be processed and schedules the requested number of Scheduler-jobs to work on the separate chunks. Thereby completing the task in several, smaller batches.
In short: Yes. By using dbms_parallel_execute and a parallellization of 20 and loading approximately 1000 blocks at the time, the job completed in 13,5 minutes. A parallellity of 10 completed in about 18 minutes.
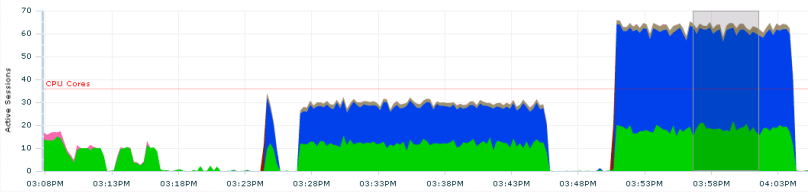
The graph below shows a job with a parallellity of 10 starting at about 3:36PM and the same with a parallellity of 20 starting at about 3:50 PM. Considering this job might be running together with other jobs, the increased I/O pressure might not be worth the 5 minutes gained.
I still thought the query itself might be quicker, so I altered the parallel-settings of the mapping-tables from a parallellity of 4 to no parallel. The result was that the plan changed from full scans of the mapping-tables and hash joins to using nested loops.
Running with a parallellity of 20 (jobs) gave a much more I/O-friendly graph and the job finished in just over 10 minutes (the left of the two areas below):

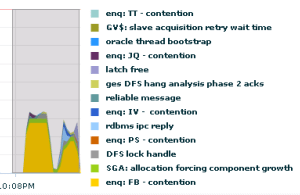
Trying to push to 30 parallel jobs (the right one of the two above) ended up in lots of waits on “enq: FB – contention” on the target side:
A nice, simple example of dbms_parallel_query can be found in the 12.1 documentation, and I used that as a starting point, changing the update to an insert over a db-link.
Another thing worth mentioning is that you can, optionally assign a job-class to the parallel_execute task. This lets you control a mix of jobs through the Resource Manager.
More on the enq: FB – contention can be found in Jonathan Lewis’ blogpost on the subject.
