Large joins may use full scans and hash joins. If your tables are large enough, this will fill up your process working memory and start spilling to your temp-tablespace. At that time a few important effects come into play:
- Your intermediate resultsets are being written and read, possibly several times.
- Your I/O capacity degrades because of this extra work.
- You might run out of temp space.
- Time is ticking away.
The graph below shows the anatomy of a large hash-join (32 tables). We’re really not using cpu, but we’re hitting disk quite a few times.
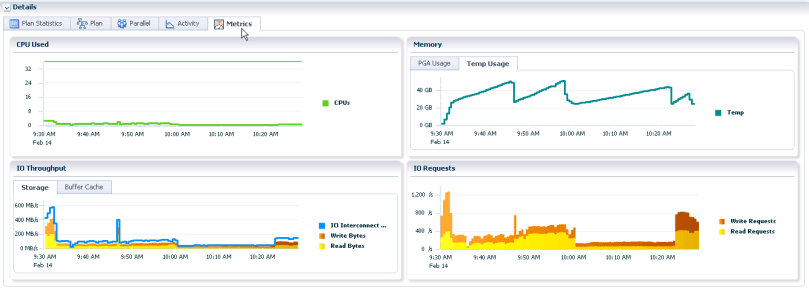
Playing around with this, I’ve noticed that some hash-join operations may very well finish in a shorter amount of wall time, due to effective utilization of the the different parts of the system. But the total capacity of the system will be heavily infuenced. In other words: It doesn’t necessary work well in a mix with other jobs.
On the other hand, some nested loop operations might take longer, but can consume significantly less I/O (but may use more CPU).
When you’re mixing several large jobs like this it might be worth to keep an eye up for it and consider changing the join-plans for your queries. Also – your operations may benefit of being resumable if you run out of temp-space underway.
